
Most models utilized by artificial intelligence frameworks today are particular. A lingering 2D organization may be a decent choice for picture handling, however is, best case scenario, inexactly fit to different kinds of information —, for example, the Lidar signals utilized in self-driving vehicles or the force utilized in robots.
Besides, standard models are frequently planned in light of just a single errand, and frequently lead specialists to twist around in reverse to reshape, misshape, or change their bits of feedbacks and results with the expectation that the standard design will figure out how to appropriately deal with their concern. Managing more than one sort of information, like the sounds and pictures that make up recordings, is significantly more mind boggling and normally includes complex, hand-tuned frameworks worked from various parts, in any event, for basic undertakings. As a feature of DeepMind's central goal to settle insight to propel science and humankind, we need to construct frameworks that can take care of issues that utilization many sorts of information sources and results, so we've started to investigate a nonexclusive, flexible design that can deal with a wide range of information.

In a paper presented at ICML 2021 (International Machine Learning Conference) and published as preprint on arXiv, we introduced Perceiver, a general-purpose architecture that can process data including images, raster clouds, audio, video, and their combinations. . While the Perceiver could handle many types of input data, it was limited to tasks with simple output, such as classification. It describes a new initial version on arXiv of Perceiver IO, which is a more generic version of the Perceiver architecture. Perceiver IO can produce a variety of outputs from many different inputs, making it applicable to real-world areas such as language, vision, and multimedia comprehension as well as to demanding games such as StarCraft II. To help researchers and the machine learning community in general, we’ve now opened up the code.

Observers build on Transformer, an architecture that uses a process called “attention” to map inputs into outputs. By comparing all the input elements, Transformers process the input based on their relationships to each other and to the task. Attention is simple and broadly applicable, but switches use attention in a way that can quickly become expensive as the number of inputs grows. This means that the converters work fine with inputs containing a few thousand items at most, but common forms of data such as pictures, videos, and books can easily contain millions of items. Using the original Perceiver, we’ve solved a key problem for a generic architecture: scaling the switch’s attention operation to very large inputs without making domain-specific assumptions. Perceiver does this by using attention to first encode the input into a small latent array. This latent matrix can then be processed at a cost that is independent of the size of the input, enabling Perceiver’s memory and computational needs to grow gracefully as the input grows larger, even for particularly deep models.

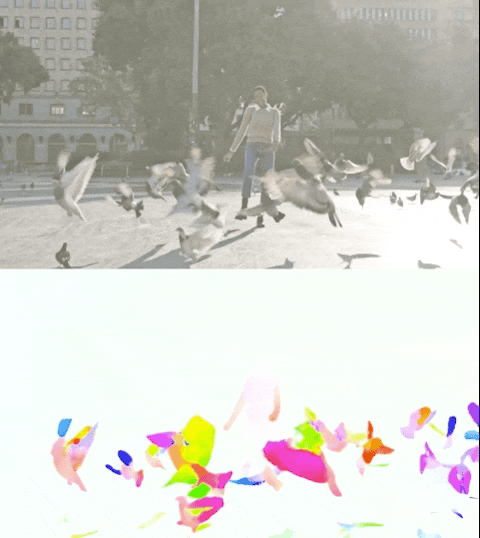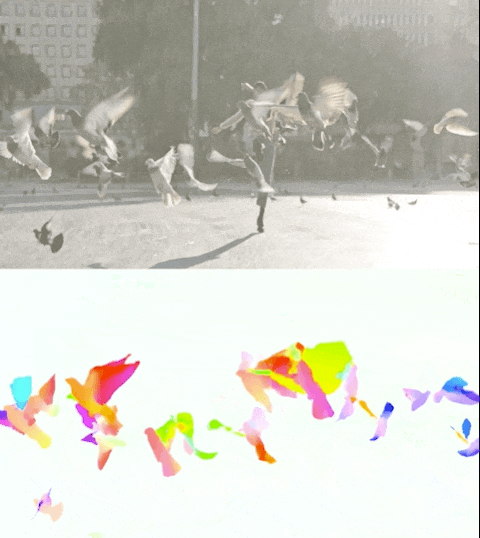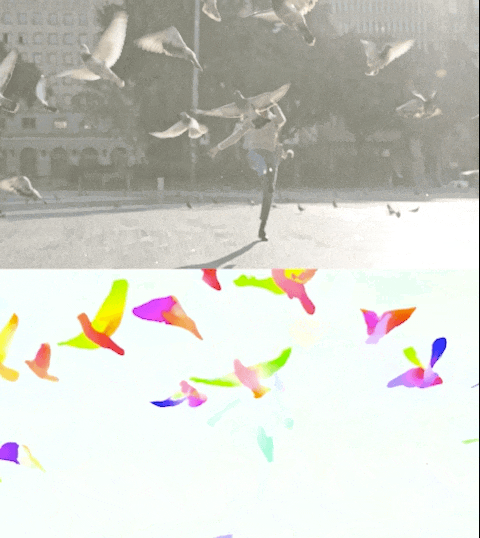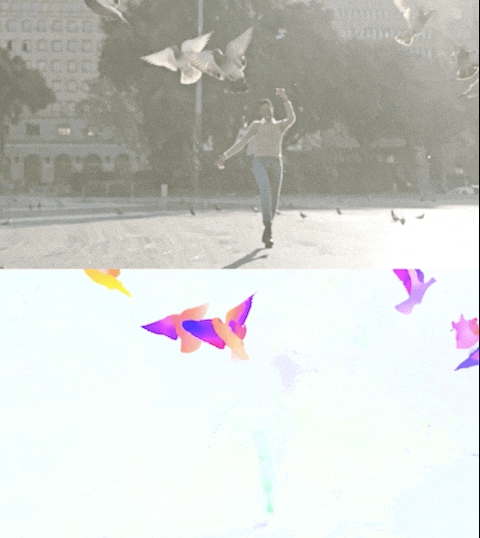


Figure 3. Perceiver IO yields state-of-the-art results in the challenging task of estimating optical flow, or tracking the movement of all pixels in an image. The color of each pixel shows the direction and motion speed estimated by Perceiver IO, as shown in the legend above.
This “agile growth” allows the Perceiver to achieve an unprecedented level of generality – it is competitive with domain-specific models based on image-based criteria, 3D point clouds, sound and images combined. But because the original Perceiver produced only one output per input, it wasn’t as versatile as the researchers needed it to be. Perceiver IO fixes this problem by using attention not only to encode to a latent array but also to decrypt from it, giving the network great flexibility. Perceiver IO is now expanding to include a wide variety of inputs And outputs, and can even handle many tasks or data types simultaneously. This opens the door to all kinds of applications, such as understanding the meaning of text from each of its letters, tracking the movement of all points in an image, processing the sound, images and labels that make up a video clip, and even playing it. games, all while using a single architecture that’s simpler than the alternatives.
In our experiments, we’ve seen Perceiver IO work across a broad range of modular domains—such as language, vision, multimedia data, and games—to provide an off-the-shelf way to handle many types of data. We hope that the latest version of the initial version and the code available on Github will help researchers and practitioners address issues without having to invest the time and effort to build custom solutions using specialized systems. As we continue to learn from exploring new types of data, we look forward to further improving this general-purpose architecture and making it faster and easier to solve problems via science and machine learning.