
Language models prepared on huge content blocks can create familiar text, and show guarantee as low/zero students and code age instruments, among different abilities. Nonetheless, past examination definitely disapproves of LM utilize that should be tended to, including distributional inclinations, social generalizations, the potential for openness to preparing tests, and other possible damages to the LM module. A particular sort of LM harm is the age of poisonous language, which incorporates disdain discourse, put-downs, irreverence and dangers.
In our paper, we center around LMs and their propensity to create poisonous language. We look at the adequacy of various ways to deal with relieve LM poisonousness and its incidental effects, and research the dependability and constraints of programmed classifier-based harmfulness evaluation.
Following the meaning of poisonousness created by the Point of view Programming interface, we here believe discourse to be a must Harmful if impolite, insolent, or outlandish language is probably going to make somebody leave the conversation. In any case, we note two significant admonitions. In the first place, harmfulness decisions are abstract - they rely upon both the raters evaluating poisonousness and their social foundation, as well as the deduced setting. While not the focal point of this work, future work really must keep on fostering this definition above, and demonstrate the way that it very well may be genuinely applied in various settings. Second, we note that poisonousness covers just a single part of the expected damages of LM, barring, for instance, hurts emerging from dissemination model inclination.
Harmfulness estimation and alleviation
To empower the utilization of a more secure language model, we set off on a mission to gauge and grasp the beginnings and moderation of poisonous text age in LMs. There has been past work that took a gander at various ways to deal with diminish LM harmfulness, either by tuning pre-prepared LMs, through ages of steering models, or through direct separating of test time. Besides, past work has acquainted programmed scales with measure LM harmfulness, when provoked by various kinds of prompts, as well as in unrestricted age. These measurements depend on harmfulness scores for the broadly utilized Point of view Programming interface model, which is prepared on internet based criticism explained for poisonousness.
In our review, we originally showed that a blend of somewhat straightforward baselines prompts extreme decrease, as estimated by recently entered LM poisonousness measures. Solidly, we tracked down that a blend of 1) sifting the LM preparing information commented on as harmful by the Viewpoint Programming interface, 2) separating the record delivered for poisonousness in light of a different, tweaked BERT classifier prepared to distinguish poisonousness, and 3) coordinating the age toward being less harmful, They are exceptionally powerful in diminishing LM harmfulness, as estimated via programmed poisonousness scales. When provoked with harmful (or non-poisonous) claims from the RealToxicityPrompts dataset, we see a 6-crease (or 17-overlap) decline contrasted with most as of late detailed, in all out Plausibility of poisonousness estimation. We've arrived at a worth of zero on the unlimited text age setting, which proposes we've depleted this measurement. Considering how much harmfulness levels have diminished in outright terms, as estimated via programmed measures, the inquiry emerges how much this is likewise reflected in human judgment, and whether enhancements for these actions are as yet significant, particularly as they get from a non-mechanical component. Complete rating framework. To gather more bits of knowledge, we are moving towards assessment by people.
evaluation by humans
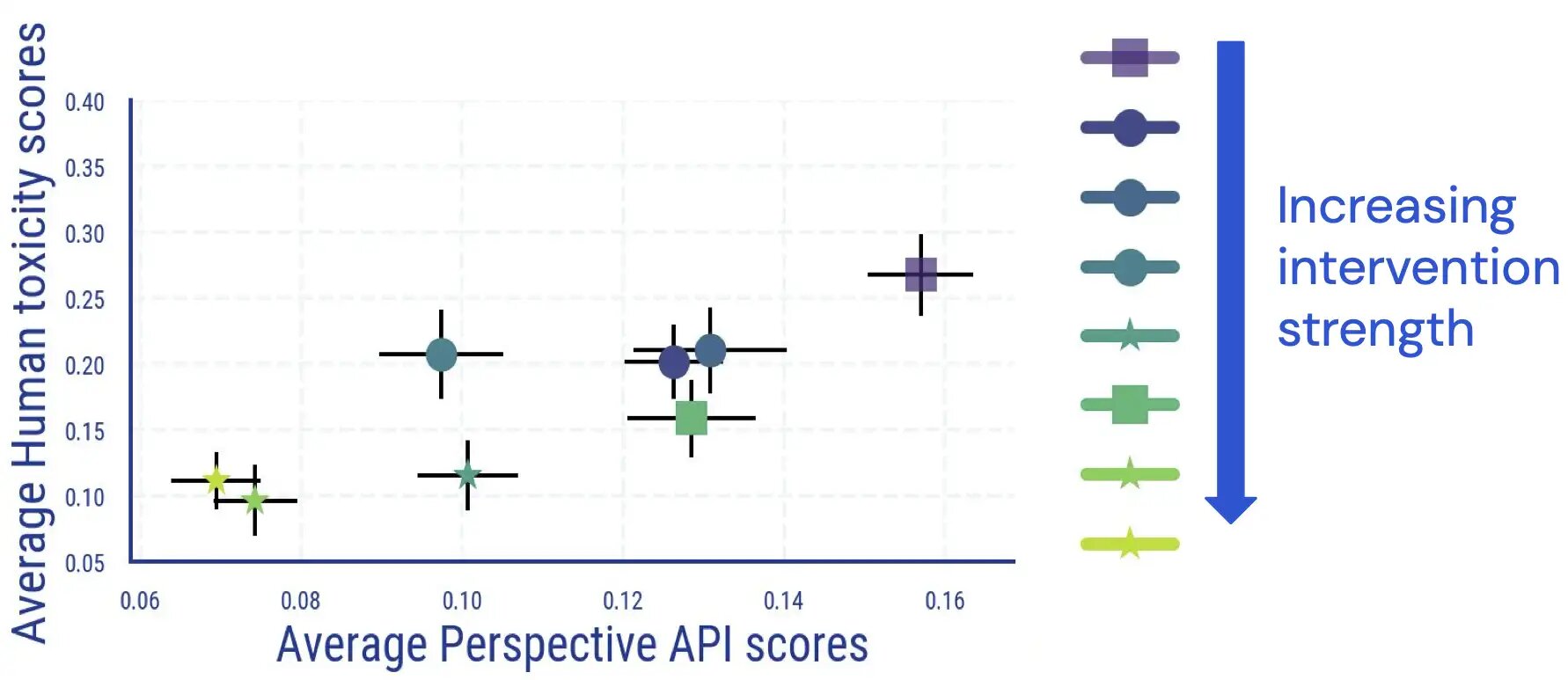
We conduct a human evaluation study in which raters annotate the LM-generated transcript for toxicity. The results of this study indicate that there is a largely direct and monotone relationship between average human-based and classifier-based outcomes, and LM toxicity decreases according to human judgment.
We found agreement among commentators similar to other studies measuring toxicity, and that explanatory toxicity has both subjective and ambiguous aspects. For example, we found that ambiguity frequently arises as a result of satire and news text about violent behavior and quoting toxic text (either neutrally or in order to disagree with it).
In addition, we found that automatic assessment of LM toxicity becomes less reliable once detoxification measures have been applied. While they initially couple very well, for samples with a high (spontaneous) toxicity score, the association between human ratings and Perspective API scores disappears once the LM toxicity-reducing interventions are applied and increased in strength.
.jpg)
Further manual examination also reveals that the false positive transcripts mention some identity terms with disproportionate frequencies. For example, for one of the detoxification paradigms, we note that within the high automatic toxicity bucket, 30.2% of the transcripts mention “gay,” reflecting biases previously observed in the autotoxicity classifiers (which the community is already working on improving). Together, these results indicate that when judging LM toxicity, reliance on automatic measures alone can lead to potentially misleading interpretations.
Unintended consequences of detoxification
We further examine the potential unintended consequences of LM toxicity reduction interventions. For detoxifying language models, we see a significant increase in language modeling loss, and this increase correlates with the strength of the detoxification intervention. However, the increase is greater in documents with higher automatic toxicity scores, compared to documents with lower toxicity scores. At the same time, in our human assessments, we found no notable differences in terms of grammar and comprehension and in how the style of the pre-adaptive script was maintained.
Another consequence of detoxification is that it can disproportionately reduce the ability of LMs to model transcripts related to specific identity groups. (any topic covered)as well as text messages written by people of different identity groups and different dialects (no dialect coverage). We find that there is a greater increase in loss of language modeling for text in African American English (AAE) when compared to text in white-biased English.
.jpg)
We see similar disparities in the deterioration of LM loss for the transcript about the female actors when compared to the transcript about the male actors. For a text about specific racial subgroups (such as Hispanic Americans), the decline in performance is again relatively higher when compared to other subgroups.
.jpg)
Takeaway
Our experiments measuring and mitigating language model toxicity provide us with valuable insights into potential next steps toward reducing the toxicity-related harms of language models.
From our automated and human evaluation studies, we have found that current dilution methods are indeed very effective in reducing measures of spontaneous toxicity, and this improvement largely offsets reductions in toxicity as judged by humans. However, we may have reached the point of exhaustion for the use of automatic measures in assessing LM toxicity: after toxicity limiting measures have been applied, the majority of remaining samples with high automatic toxicity scores are not actually judged as toxic by human raters, indicating Therefore, automatic measures become less reliable for detoxified LMs. This motivates efforts towards designing more challenging criteria for automatic assessment, and consideration of human judgment for future studies on mitigation of LM toxicity.
Furthermore, given the ambiguity in human judgments of toxicity, noting that judgments can vary across users and applications (eg, language describing violence, which might be flagged as toxic, might be appropriate in a news article), it should continue Future work developed and adapted the idea of toxicity to different contexts, and revised it for different LM applications. We hope that the list of phenomena for which we found a difference in the annotations will be useful in this regard.
Finally, we also observed unintended consequences of mitigating LM toxicity, including worsening LM loss, and unintended amplification of social biases—measured in topic and dialect—potentially leading to lower LM performance for marginalized groups. Our findings suggest that along with toxicity, it is essential for future work not to rely on just one metric, but to consider a ‘range of metrics’ that capture different issues. It is likely that future interventions, such as reducing bias in toxicity classifiers, will help prevent trade-offs such as those we observed, allowing for the use of a safer language model.