
As an example of a social environment, consider how self-driving cars on the road interact with other cars. Each car has an incentive to transport its passengers as quickly as possible. However, this competition can lead to poor coordination (road congestion) which negatively affects everyone. If the cars operate cooperatively, more passengers may arrive at their destination more quickly. This conflict is called a social dilemma.
However, not all interactions are social dilemmas. For example, there synergistic Interactions in open source software The net result is zero Interactions in sport, f Coordination problems It is at the heart of supply chains. Navigating each of these situations requires an entirely different approach.
Multi-agent reinforcement learning provides tools that allow us to explore how artificial agents interact with each other and with unfamiliar individuals (such as human users). This class of algorithms is expected to perform better when tested for their social generalization capabilities than others. However, to date, there has been no systematic evaluation standard to assess this.
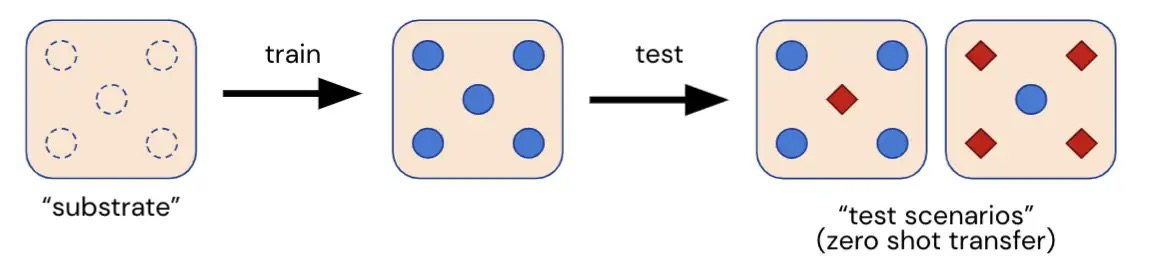
Here we present the Melting Pot, a scalable evaluation suite for multifactor reinforcement learning. The Melting Pot assesses generalization to novel social situations involving both familiar and unfamiliar individuals and is designed to test a wide range of social interactions such as: cooperation, competition, deception, reciprocity, trust, stubbornness etc. The Melting Pot offers researchers a set of 21 MARL (multifactor game) “substrates” to train agents on, and more than 85 unique test scenarios to evaluate these trained agents. The performance of the agents in these test scenarios determines whether the agents:
- perform well across a range of social situations in which individuals depend on one another,
- Interact effectively with unfamiliar individuals who were not seen during training,
- Passing the generalization test: answering positively the question “What if everyone acted this way?”
The resulting score can then be used to rank different multifactorial RL algorithms by their ability Circular To narrate social situations.
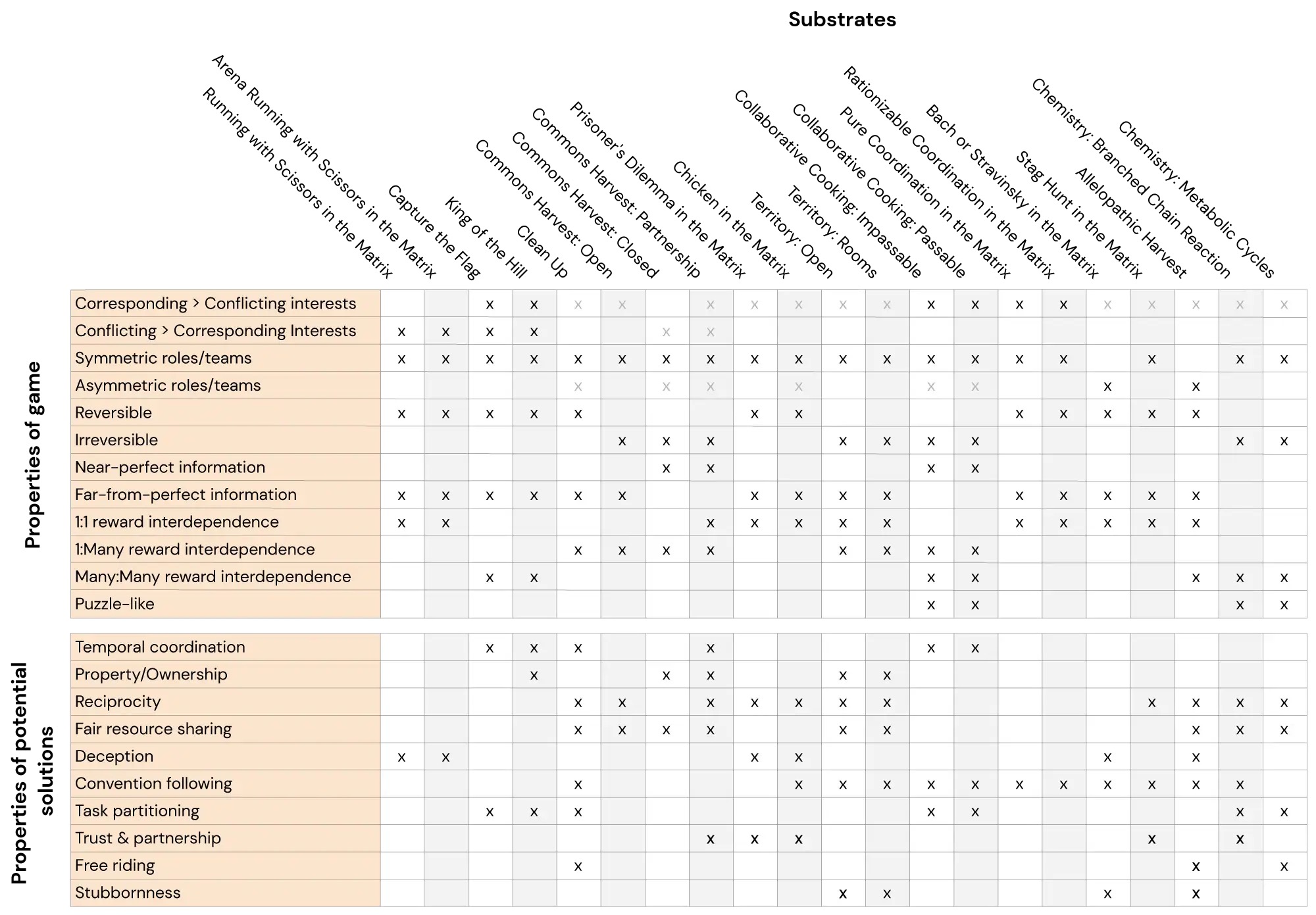
We hope the Melting Pot will become a standard for multifactor reinforcement learning. We plan to maintain it, and we will expand it in the coming years to cover more social interactions and mainstreaming scenarios.
Learn more from our GitHub page.